

层次结构的核心灵感:局部性原理 #
局部性原理是一切故事的开始。把处理器想象为一位期末周试图读懂《电路理论》的学生。他读这本书时有一个特点:
- 时间局部性:课本不是小说,这位学生不能把每个字都只读一次。相反,他会在某个章节反反复复地来回读,直到搞懂后再进行下一个章节。(某一时刻用到的数据,在短期内很可能再次被用到)
- 空间局部性:复习是有逻辑的,看了 P100 后更可能看 P101,而不是 P100、P10、P200 这样跳着看。(一旦用过某个地址的数据,则很可能要用到相邻地址的数据)
CPU 的行为也大抵如此。由于程序中循环结构大量存在,现在用到的指令和数据在未来短时间内很可能再次用到,存在时间局部性。由于相同上下文的数据经常被放在相邻的地址,CPU 对内存的访问存在空间局部性。
局部性原理是存储器层次结构的核心灵感。试想一个没有时空局部性的世界:对内存的访问完全随机,符合均匀分布,在这个世界里,最快的缓存里放的数据被访问的概率和最慢的同样高,即使数据被从低一级的存储器提升到更快的缓存,将来也很难再用到;这样一来,memory hierarchy 就完全没有意义,只是徒增了数据迁移的开销而已。
多级存储器是怎么运行的 #
计算机运行时,最远、最慢、最大的存储器拥有最完整的信息;最近、最快、最小的存储器只保存临时用到的部分数据,并随时按需要从低级存储器中提取和替换数据。
如果我们承认时间和空间的局部性,就有一个 naive 但有效的想法:起初先把所有数据放在最慢的磁盘上,当 CPU 需要用到某些数据时,会发现(从上到下)寄存器、cache、主存中均没有这个数据,于是将用到的这部分数据依次从磁盘提取到主存、cache、寄存器中,并期待由于时间局部性原理,将来还会再次用到这个数据(那时候就已经在快速存储器里了);也从空间局部性原理出发将和它相邻的一些数据块“顺便”取到更快的存储器中。反之亦然:当 cache 满了,就将最老最没用的数据驱逐到主存中,如果主存也满了就驱逐到磁盘中。
未来我们会看到,这一系列 naive 的机制实现起来并不是非常 naive。
- 寄存器和 cache 的数据交换是硬件实现的,具体来说是 CPU 的 Load / Store 指令;
- cache 与内存的数据交换同样是硬件实现的;
- 内存与磁盘的数据交换是软硬件协同实现的(缺页中断);
- 决定哪些数据是“又老又没用”的、该被驱逐的,有许多算法,最常见的比如 LRU(Least Recently Used)。它不仅在体系结构中大放异彩,在软件设计中亦有应用。
Cache Placement #
今天,就让我们暂时聚焦于 memory hierarchy 中离寄存器最近的一级,也就是 cache。Cache 是处理器核心(core)与外部的交界。再往里,寄存器的实现是直接与 core 耦合的;再往外,主存一般不直接与 core 产生交互。
我相信笼统地描述 cache 的宏观行为并不能满足本楼读者的好奇心。为了近距离搞懂 cache 的工作原理,我能提出的最佳问题是:从主存储器中提取上来数据究竟是以何种布局放在 cache 中的?
放置策略(cache placement)有很多种,在此先介绍一种最通用、最常见的策略,然后我们在后文从它出发拓展到一些特殊情况。这种策略就是组相联(set-associative cache)。
首先明确一个大前提:cache 是比主存小的,而且小很多,因此,函数 memory_address -> cache_placement_address 一定是一个多对一的关系,即某个 cache 的位置是可能对应多个内存地址的。一个自然的想法是对内存地址取模。比如一共有 8 个 cache “槽”,就把内存地址 mod 8,结果就是存放位置。我们会在这个基础上做一些修改。
- 数据分组(Block Size):没必要精细地管理每个字节。可以将若干字节(比如 4 字节)打包成一个 block 来处理,让 block 成为 cache 管理数据的最小粒度。这样,地址的最低位就不重要了(在本例中就是最低 2 位)。
- 多路存放(Associativity):打个比方,假如已经确定了“地址 A 应该存放在 cache 的第 3 个位置”,实际实现时,“第 3 个 cache 槽”可以包含多个平等的重复位置(例如 2 个),地址 A 对应的数据可以放在调用时空闲的任何一个位置上,也就是把“第 3 个位置”的措辞改为“第 3 组 / Set-3”。这样一来,当地址 A 对应的数据存在时,如果地址 B 对应的数据也需要放进 cache,且(很不幸)B 也映射到第 3 组,那么这个新数据就可以放在第 3 组空闲的位置中,而不必立即驱逐旧数据。
- 命中验证(Tag):假设处理器现在需要提取地址 A 的数据,且 cache 中对应的 Set-3 也确实有数据。如何验证 cache 中的数据真的是地址 A 的数据呢(还记得我们说过多对一的关系吗)?最简单的方法是将地址的最高若干位一起存放起来。在下面这张图中,地址总长度为 14 位,一共有 31 个 set,那么(除去数据分组导致的最低 2 位无效后)参与模运算的地址长度为 12 位;然而,模 31 运算的结果显然只取决于最低 5 位,因此可以把高 7 位作为 tag 存放进 cache 中。这样一来,尽管
0000000 00011和0000001 00011都对应 Set-3,它们放进 cache 时一同存放的高 7 位是不同的。我们只需要比较地址 A 的高 7 位(tag),和现存 cache 中的 tag,就可以分辨缓存到底有没有命中了。
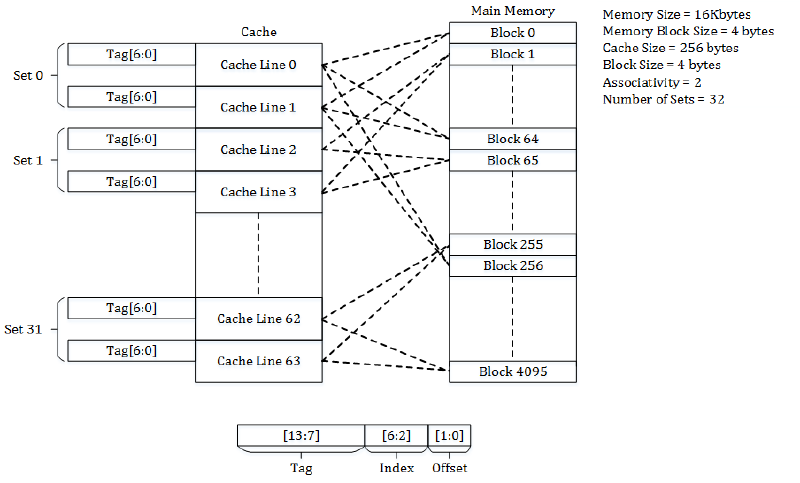
综上所述,我们再总体解释一下这张图:
- 为了简便,地址总长度只有 14 位,实际运行的计算机不会这么少。
- 图中 block size 为 4,也就是说地址的最低 2 位(Offset)对于 cache 来说是无效的。
- Associativity 为 2,也就是说一个 set 内部有两个候选位置,数据可以放在任何一个空闲位置上;没有空闲位置的话,就会发生驱逐。
- Index 共 5 位,这是因为 number of sets = 31,从 0 到 31 编号最多会用到 5 位二进制数。所谓 index 其实就是 真正决定取模结果的部分。
- Tag 共 7 位,这是简单的减法得到的。
- Block 0 放在 Set 0,Block 1 放在 Set 1,……,Block 31 放在 Set 31,Block 32 放在 Set 0,周而复始。
- Block 0 可以放在 Set 0 的任何一个位置上(Cache Line 0、1);其他同理。
其他放置策略 #
从组相联策略出发,我们可以推出一些特殊情况:
- 如果 number of sets = 1,也就是说全局只有 1 组,所有数据都混在一起,只靠 tag 区分,这就是 全相联策略。
- 如果 associativity = 1,每个 set 内部仅有一个位置,数据一旦决定好组后便没有其他可能,这就是 直接相联策略。